Non ci sono articoli nel tuo carrello.
Retrieval-Augmented Generation (RAG) allows Large Language Models (LLMs) to provide context-aware answers by retrieving information from an external vector database. In this post, we’ll walk through a complete n8n workflow that builds a chatbot capable of answering company policy questions using Pinecone Vector Database and OpenAI models.
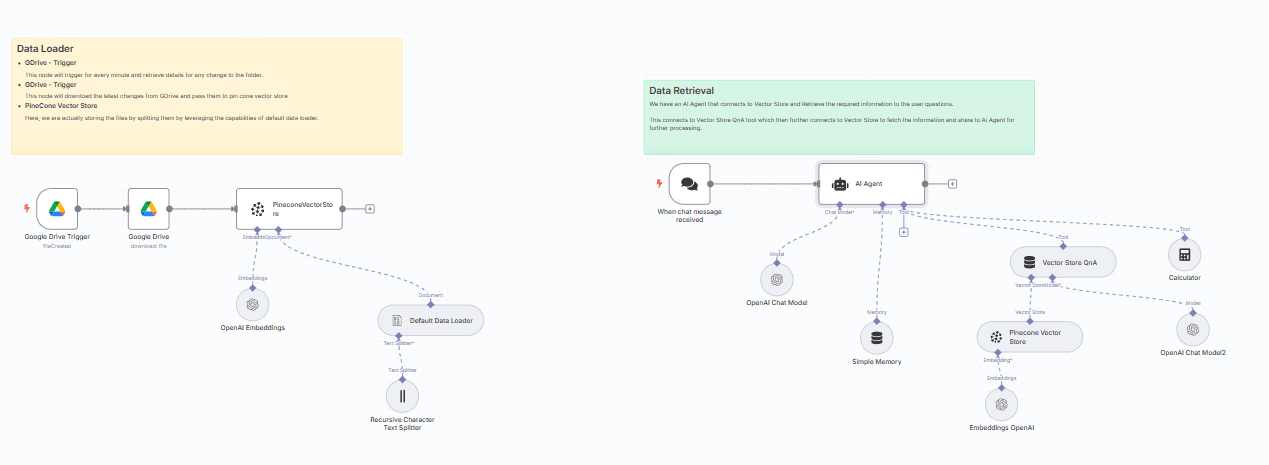
Our setup has two main parts:
This workflow section handles document ingestion. Whenever a new policy file is uploaded to Google Drive, it is automatically processed and indexed in Pinecone.
Nodes involved:
Google Drive Trigger
Watches a specific folder in Google Drive. Any new or updated file triggers the workflow.
Google Drive (Download)
Fetches the file (e.g., a PDF policy document) from Google Drive for processing.
Recursive Character Text Splitter
Splits long documents into smaller chunks (with a defined overlap). This ensures embeddings remain context-rich and retrieval works effectively.
Default Data Loader
Reads the binary document (PDF in this setup) and extracts the text.
OpenAI Embeddings
Generates high-dimensional vector representations of each text chunk using OpenAI’s embedding models.
Pinecone Vector Store (Insert Mode)
Stores the embeddings into a Pinecone index (n8ntest), under a chosen namespace. This step makes the policy data searchable by semantic similarity.
👉 Example flow: When HR uploads a new Work From Home Policy PDF to Google Drive, it is automatically split, embedded, and indexed in Pinecone.
Once documents are loaded into Pinecone, the chatbot is ready to handle user queries. This section of the workflow connects the chat interface, AI Agent, and retrieval pipeline.
Nodes involved:
When Chat Message Received
Acts as the webhook entry point when a user sends a question to the chatbot.
AI Agent
The core reasoning engine. It is configured with a system message instructing it to only use Pinecone-backed knowledge when answering.
Simple Memory
Keeps track of the conversation context, so the bot can handle multi-turn queries.
Vector Store QnA Tool
Queries Pinecone for the most relevant chunks related to the user’s question. In this workflow, it is configured to fetch company policy documents.
Pinecone Vector Store (Query Mode)
Acts as the connection to Pinecone, fetching embeddings that best match the query.
OpenAI Chat Model
Refines the retrieved chunks into a natural and concise answer. The model ensures answers remain grounded in the source material.
Calculator Tool
Optional helper if the query involves numerical reasoning (e.g., leave calculations or benefit amounts).
👉 Example flow: A user asks “How many work-from-home days are allowed per month?”. The AI Agent queries Pinecone through the Vector Store QnA tool, retrieves the relevant section of the HR policy, and returns a concise answer grounded in the actual document.
By combining n8n automation, Pinecone for vector storage, and OpenAI for embeddings + LLM reasoning, we’ve created a self-updating RAG chatbot.
This setup can easily be adapted for other domains — compliance manuals, tax regulations, legal contracts, or even product documentation.